That study about language looks interesting. Can you trust the results?
Lots of researchers are using big data to discover amazing things about language. But big data can bring big trouble if researchers don’t look out for some common traps. What should they — and all of us — be watching out for?
We’ll find out on this episode of Talk the Talk.
Listen to this episode
You can listen to all the episodes of Talk the Talk by pasting this URL into your podlistener.
http://danielmidgley.com/talkthetalk/talk_classic.xmlAnimations
by the Mystery Animator
Cutting Room Floor
Kylie phoned her cat from the studio. Wouldn’t that confuse a cat?
Burger King hacks Google on one of their ads.
There’s a bonus Word of the Week! In honour of the jailing of Pharma Bro (or Douche) Martin Shkreli, we look into ‘Bro’. And we respect the Wu-Tang Clan.
Also at https://www.patreon.com/posts/17721076
Patreon supporters
We’re very grateful for the support from our burgeoning community of patrons, including
- Termy
- Jerry
- Matt
You’re helping us to keep the talk happening!
We’re Because Language now, and you can become a Patreon supporter!
Depending on your level, you can get bonus episodes, mailouts, shoutouts, come to live episodes, and of course have membership in our Discord community.
Show notes
‘Virtual moron-idiot’: Telstra’s support chatbot backfires
https://www.smh.com.au/technology/virtual-moron-idiot-telstra-s-support-chatbot-backfires-20180309-p4z3jm.html
‘Virtual moron-idiot’: Telstra’s support chatbot backfireshttps://t.co/EKfF7Uw6pc
Hat tip @parisba
— Ben Grubb 🐛 (@bengrubb) 8 March 2018
Alexa randomly laughing compilation
https://www.youtube.com/watch?v=p8phGxzUC_Y
Alexa’s Creepy Laughter Is a Bigger Problem Than Amazon Admits
https://www.fastcodesign.com/90163588/why-alexas-laughter-creeps-us-out
Video Compilation of Alexa’s Creepy Laugh Goes Viral
http://twistedsifter.com/videos/alexa-creepy-laugh-video-compilation/
Amazon has a fix for Alexa’s creepy laughs
https://www.theverge.com/circuitbreaker/2018/3/7/17092334/amazon-alexa-devices-strange-laughter
Fake news spread by humans more than bots
http://www.straitstimes.com/world/united-states/fake-news-spread-by-humans-more-than-bots
What Those Cornell Pizza Studies Teach Us About Bad Science
https://www.lifehacker.com.au/2018/03/what-those-cornell-pizza-studies-teach-us-about-bad-science/
Roberts: Robust, Causal, and Incremental Approaches to Investigating Linguistic Adaptation
https://www.frontiersin.org/articles/10.3389/fpsyg.2018.00166/full
Simpsons: Embiggen
https://www.youtube.com/watch?v=FcxsgZxqnEg
A made-up word from a 22-year-old ‘Simpsons’ episode has finally made it into the dictionary
https://www.businessinsider.com.au/embiggen-simpsons-2018-3
A Major Dictionary Has Officially Added Emoji
http://time.com/5186512/emoji-dictionary/
What does 💅 nail-polish emoji mean?
http://www.dictionary.com/e/emoji/nail-polish-emoji/
Embiggening the role of a playful neolexeme
http://languagelog.ldc.upenn.edu/nll/?p=2677
Transcript
[Transcript provided by SpeechDocs Podcast Transcription]
DANIEL: Hello, and welcome to this episode of Talk the Talk, RTRFM’s weekly show about linguistics, the science of language. For the next hour, we’re going to be bringing you language news, language technology, and some great music. Maybe we’ll even hear from you. My name’s Daniel Midgley. I’m here with Ben Ainslie.
BEN: Good morning.
DANIEL: And Kylie Sturgess.
KYLIE: G’day, everyone.
DANIEL: Lots of researchers are using big data to discover amazing things about language. But big data can bring big trouble if researchers don’t look out for some common traps. What should they — and all of us — be watching out for? We’re going to find out this episode of Talk the Talk.
BEN: Daniel, you do know how to touch me in all the right places.
DANIEL: What are you talking about?
BEN: I mean, you know… you know I love stories about the inevitable machine overlords. I love them! I love them so much and, like — let’s put it out there — Big Data is definitely one of the pillars of the coming digital apocalypse. Like, there’s just no two ways about it.
DANIEL: I was thinking something a little different. I was thinking of the way that academics in all fields, not just computer science and not just linguistics, are starting to turn to big-data techniques. I’m thinking the digital humanities and lots of other things as well. So it’s a good idea for us to know what to watch out for.
BEN: Indeed. But before we delve too deeply into the concerning trends of the digital decline, let’s find out what’s been going on in the world of linguistics in the week gone past.
DANIEL: This is surprisingly topical. Kylie, you alerted me to this story.
KYLIE: I thought it was hilarious. Apparently, a bot has gone a little bit wild, sending people into fits of rage because they just won’t do what it’s supposed to do when you phone up and say “I want to speak to a human being.”
BEN: Ah, yup. Okay, we’ve all been here.
DANIEL: This is in the news especially because it happened with Telstra, the Australian telco. Telco? Telecom?
BEN: Telecommunications company. For those outside of Australia, the thing to remember about Telstra, as it is now known, is: Australia used to be huge — huge — on nationalised industries, nationalised utilities in particular. So Telecom, which was what Telstra used to be, was government-owned and it controlled all the phones in Australia. Right? Like, that’s just the way it was. So then they privatized it, introduced competition, allowed other telecommunication companies into the mix, and Telstra is what’s, like, left of this first granddaddy of telecommunications.
KYLIE: And now we all get together at barbecues, and complain about whose provider is the worst. “Oh, my god, you wouldn’t believe… my phone won’t work!”
BEN: We definitely have a first-world-problem-off. “I was taking a dump, and I couldn’t play my game!”
KYLIE: “It kept ringing! I didn’t know what to do!”
BEN: It was really difficult!
DANIEL: Socialist Corner with Daniel. My version of the story is the they had a functioning industry, and the Liberal Government wanted to sell it off and get the money for their friends. So they did. That belonged to us and we owned it. I’m going to come out for a programme of aggressive renationalisation.
BEN: [LAUGHS] Oh, that’s going to be popular!
DANIEL: Utilities. I’m talking banks. Let’s get it all back.
BEN: Okay.
DANIEL: Thank you.
BEN: I’m on board.
KYLIE: Let’s see if we can recreate the experience of Codi. Codi is Telstra’s way of connecting with people. It’s a chatbot.
BEN: Right, it’s just the name they’ve given to their version of the, like: “To talk to a whatever, please say what you want.”
KYLIE: “Hello, this is Codi.” Many people were unimpressed, and they were throwing shade at Telstra’s efforts to make use of this artificial intelligence. Hundreds of thousands of customers have taken to social media to complain. Here’s an example: A script that I’ve taken from @parisba. So, ParisBA on Twitter. You be Paris, Ben.
BEN: Okay.
KYLIE: And I’ll be Codi, the helpful assistant. From the top.
BEN: So, I have a feeling that we’re starting mid-conversation here, because this does not sound like when you start.
KYLIE: You’ve been doing this for a while, Paris.
BEN: Human. Human! Human!! Human human human.
KYLIE: If you need help with anything else, please let me know.
BEN: Human! Please give me a human. Please?
KYLIE: I’m here to help with your Telstra inquiries. Try asking me a question.
BEN: Human. Could I speak to a human? Please?
KYLIE: Sorry, I wasn’t able to help. I’ll connect you to a human chat consultant now.
BEN: Human.
KYLIE: So I can transfer you to a human chat consultant, please provide your name.
BEN: Paris.
KYLIE: I can help with roaming, if you like. To help you further, I’m going to have to pass you on to one of our human chat consultants. Is this okay? Looks like I might need some more training on this.
BEN: Yes. Pass me to a human.
KYLIE: While I’m usually pretty good with my yes and noes, I’m not quite sure what you mean here. Let me know what else you’d like to know. Sorry I wasn’t able to help. I’ll connect you to a human chat consultant now. So I can transfer you to a human chat consultant, please provide your name.
BEN: Paris.
KYLIE: I can help with roaming, if you like!
BEN: [ANGUISHED SCREAM]
KYLIE: And so on and so on and so on.
BEN: I’m going to cop to ad-libbing the final scream. I just felt that’s where the character’s impetus took me. That is horrific. That is terrible, and that is why, whenever I’m on a chat tree of any kind like that, I just zero. I just press zero over and over and over again, and I’ve never once had it not work.
DANIEL: I often say ‘operator’. I don’t often say ‘human’. Do you think that was one thing that went wrong?
KYLIE: I spoke to someone who has worked in voice recognition software and has done this kind of coding for other companies, and their response was, “Well, yeah, this is just bad coding.” ‘Operator’ is a much more forthright word to use, rather than ‘human’. If the computer is going into too many errors, what it should be doing is, rather than responding, is recording so the operator can get an example of the audio. So poor old Paris going, “Human human human! I just need to know this“, they take that data and the human operator is able to act on it.
DANIEL: I think there’s another problem with the name Paris, because of course that has a couple of meanings. It could be a name, but it also could be the name of the city.
BEN: That’s why ‘roaming’! I didn’t even cotton on to that!
KYLIE: Really?
BEN: No.
KYLIE: Ah. “I can help you with roaming!”
DANIEL: I think the take-away from this is that automatic speech recognition has gotten actually really really good.
BEN: Anyone with a phone knows that.
DANIEL: What is terrible here is the dialogue management. It just doesn’t seem to figure out where the flow should go, and that’s where they need to put their effort. There is something else that’s happening, as far as Amazon’s home computer thing Alexa.
BEN: I don’t know a lot about these things because I have an Android phone, a Google phone, and I’ve had the ability to, like, ‘okay Google’ my way through whatever for a couple of years now, and I don’t use it. Not because I’m averse, but just because I don’t feel like it helps me.
DANIEL: It’s fun to play with. My sister had one. I was at her place and I was like, “Hey Alexa, play something by the Beatles,” and it would play ‘Something’ by the Beatles.
BEN: Ah, right.
KYLIE: I had some opportunities to speak to people who were visually impaired, and they said having Alexa or Google home devices were incredibly useful around the house. You just shout out, “Hey, I want to hear the top five news stories of the day.” Boom — it will give you the BBC rundown. Or: “What’s the weather going to be like?” Boom — it would immediately give it to you, rather than you having to search it.
DANIEL: Useful though they be, Alexa has been giving users fits lately.
BEN: Fits of laughter?
DANIEL: Fits of fear.
BEN: Oh.
DANIEL: It’s been… laughing… for no apparent reason.
BEN: Oh, that’s creepy as hell.
KYLIE: MUHUHAHAHAHAHA.
DANIEL: Let’s listen.
BEN: Oh! Okay. Oh, no — I don’t know… I don’t want to hear this all!
[DISEMBODIED HUMAN LAUGHTER]
[THE SAME DISEMBODIED HUMAN LAUGHTER]
[DIFFERENT DISEMBODIED HUMAN LAUGHTER]
BEN: Okay, well, that’s legitimately terrifying.
KYLIE: [LAUGHS]
DANIEL: Yes. Gavin Hightower on Twitter tweeted, “Lying in bed about to fall asleep when Alexa on my Amazon Echo Dot lets out a very loud and creepy laugh. There’s a good chance I get murdered tonight.”
BEN: No — see, I feel like getting murdered tonight is the good outcome! Right?
DANIEL: What’s the bad outcome?
BEN: The bad outcome is Alexa is now sentient! Right?
DANIEL: Thinking about a joke.
BEN: The people who laugh loudly randomly as you’re falling asleep are not people who are there to kill you. They’re people who are starting a years-long process of psychological warfare.
KYLIE: Just ask any toddler!
BEN: You’re gonna get, like, random pizzas just delivered to your door that you didn’t order. You’re going to have people calling up and just like asking random questions, and it’s just all Alexa slowly making you…
KYLIE: Ben! What do you think of spoons?
BEN: Exactly! Right? Killing someone in the night is not fun. Breaking someone psychologically until they do something drastic is way better.
KYLIE: Ben! Snowmen! Got an opinion?
DANIEL: So why was Alexa doing this? I think what’s happening is probably that people are saying something that sounds like ‘Alexa, laugh’.
BEN: Right.
DANIEL: And it’s interpreting it that way. But what sounds like ‘Alexa, laugh’?
BEN: Especially when you’re falling asleep?
KYLIE: Well, Amazon did acknowledge that just for some rare circumstances, it mistakenly heard the phrase ‘Alexa, laugh’, and so they’ve changed it to ‘Alexa, can you laugh?’
BEN: Right. Yeah, that’s more words.
KYLIE: In order to have less false positives.
BEN: To have less murderbots in people’s houses.
DANIEL: But if you really want trouble, skip the bots and go straight to a human. When it comes to spreading fake information, humans have bots beat.
BEN: Yes. Yeah, we are really good at being terrible.
DANIEL: The MIT Media Lab published an article in the journal Science. They examined about a hundred twenty and six thousand stories shared by three million people on Twitter over a period of ten years, and they found that fake news was more likely to be retweeted then true news by about seventy percent.
KYLIE: Are we talking about, like, Onion articles I mean you know, I retweet those all the time.
BEN: No, you’re talking about deliberately fake news, aren’t you.
DANIEL: Yes, I’m talking about the fake fake news.
BEN: Deceptful news.
KYLIE: Fakey fake news.
BEN: Deceptive news.
DANIEL: People are a problem. Kylie, what should people be doing before they hit that share button? Got any tips?
KYLIE: Obviously, you have to look around to see if it’s corroborated by any other sources.
BEN: UGH! That sounds like work, Kylie. I don’t wanna read things! I don’t even want to read the article. I want to read the headline and look at the picture and SHARE IT.
DANIEL: You know, I did this once. I got an article by some natural health person. The article was about a seven-year-old that got breast implants.
KYLIE: What? NO!
DANIEL: And it had a photo of a very busty looking seven year old. So I did a couple of things. Number one: I looked at the article to see the names, because if this is true, it would be a big deal.
BEN: Big huge news, yeah.
DANIEL: So I did a search for the names and the only article that came up was that one.
KYLIE: Yeah.
BEN: Mhm.
DANIEL: And it was World Net Daily. So that’s another strike.
KYLIE: Yeah.
DANIEL: But also, I took the photo and I figured it was photoshopped. I just did a reverse Google Image search.
KYLIE: You can do that with tineye.com. That’s a great way if you know what…
BEN: You can also just do it with Google.
KYLIE: Really?
DANIEL: Yeah, Google Image search. And I found, thankfully, an adult woman upon whose body somebody had photoshopped a child’s face.
KYLIE: Geez.
DANIEL: And it all fell apart.
BEN: Yeah. Pro tip: Like, if someone like Kylie didn’t know about it, then I feel like we need to educate the world. Any image on a computer, you can like basically right-click ‘Reverse image search’ — if you’re using Chrome, anyway.
KYLIE: Oh, cool.
BEN: Yeah.
KYLIE: I was using science, because I thought, okay, there’s a couple of places out there. I mean, snopes.com is a classic one. Even though you should even check Snopes on occasion. Always make sure that you do your own research and look around.
BEN: Mhm. Except that’s boring and dumb and hard, and I don’t want to do it, Kylie.
DANIEL: I know, but we need to get some sort of idea as to whether a source is good or not. And before we share things and spread them around, we have to do our due diligence to tamp down the spread of fake news.
BEN: I always go by boringness.
DANIEL: Truth is boring?
BEN: Yeah. If an article is super-duper long and boring, it is definitely not fake, because no one is writing that to make money. You know what I mean?
DANIEL: Yeah.
BEN: I was talking about it at a barbeque earlier today. The least sellable thing on this earth, publishing-wise, is a long thoughtful, pensive, measured piece that, like, meaningfully explores a topic. It is the worst thing you can possibly write!
DANIEL: It’s just death.
BEN: Yeah, it’s like, no one wants that!
DANIEL: So probably right!
BEN: Yeah.
DANIEL: So there you go. If you’re a human — and you probably are if you’re listening to this… although…
KYLIE: Hello, Alexa!
BEN: Everyone else: I just want you to know, I’m scared of you but I welcome you.
KYLIE: And Codi wants to know if Paris will ever call back ever!
BEN: No, Codi wants to know if we need any help with roaming.
[LAUGHTER]
DANIEL: Let’s roam over to a track and this one is Delivery Buoy with ‘Our Last Phone Call’ on RTRFM 92.1.
[MUSIC]
BEN: If you are just tuning in, it is Talk the Talk, our weekly exploration of linguistics here on RTRFM, and today we are going to be deep-diving into big data, and how it applies to the field of linguistics. It’s something we’ve kind of looked at before, but we’re really going to get into the nitty-gritty today.
DANIEL: There is one story that we’ve been looking at a lot when it comes to big data. We’ve talked to Caleb Everett from the University of Miami a number of times about his work in something called geophonetics: the idea that the climate has a very subtle effect on sounds in the world’s languages, but one that we can see if we take a look at a lot of languages.
BEN: I.e. Big data.
DANIEL: There we go. It’s a controversial idea, but I have to say it’s one that linguists are kind of into. Like when I went to the Australian Linguistics Society meeting late last year, there were some linguists who really liked the idea that non-linguistic factors can influence language. And I remember that two different researchers specifically pointed to Caleb Everett’s work.
BEN: Now is this because it’s kind of sexy? Because it’s like… in the same way that if you’ve been in a relationship for a really long time, and then like a cool new thing comes along, and just because it’s cool and it’s new, you kind of go just like, Oh, man, okay it’s pretty cool. Is that what’s going on here?
DANIEL: Now you’ve put that meme in my head. [LAUGHTER] Well, there is somebody who has gotten in touch with us, and was interested in sharing his aspect of the story and maybe give us some tips on how big data can be used responsibly. We are talking to Seán Roberts of the University of Bristol. Seán, hey, thanks for talking to us.
SEÁN: Hi, thanks for having me on.
DANIEL: Tell me about where you’re coming from with the Everett work. I know that you collaborated on one of the papers.
SEÁN: Yeah, it’s a bit of a strange story. I think you’re right that it is a very sort of exciting time for linguistics. There’s now a lot of data and not just on linguistics, but we’re able to link it to things outside of linguistics, like the climate, or aspects of culture, or economics, or anything. And so there’s a lot of possible discoveries out there to be made, sort of a bit like a gold rush; there’s more data than there are people to analyse it. So people get very excited when they see these sort of patterns.
DANIEL: And that makes it tough because almost nobody is good at linguistics and economics and sociology.
SEÁN: Yeah!
DANIEL: So everyone’s kind of operating at the limit of their expertise, I think.
SEÁN: Sure. No, that’s true, and I think an important aspect of the sort of traditional approach to linguistics is getting the details right. So you argue from case studies, you make sure all of your data is accurate, and if you’re focusing on one language or group of languages, you can kind of do that. But once you start analysing a thousand languages, you can’t be an expert in each. Some of that data is going to be wrong. And so how do you cope with that? That’s the big question.
BEN: That’s a really fascinating point which hadn’t occurred to me as the, like, the dummy lay person on the show, is this idea that you’ve got all of these people who have sort of made their living making sure that the nitty-gritty is exactly right. But when you’ve got datasets of the scale that you guys are talking about, I mean the precedence for error is much higher. Now I’m operating on the understanding that that’s fine in big data because there’s just so much data that the patterns are really really clear. But it’s sounding like you’re saying, oh, maybe not so much.
DANIEL: The analogy that I like to use is playing sudoku. And the linguists are looking at the the grid and saying, okay, well this box needs a nine, and there’s only a couple places where that can go. It can go here or here… and then they work out the puzzle that way. But it’s like the big data folks are going: All right, we took a look at three million sudoku games and we found out there’s a very strong tendency for a three to go in this box. And so we were able to induce the entire puzzle to an accuracy of eighty-five percent. So that’s very good.
SEÁN: I totally understand that point. And I can understand why someone who spent their whole life working on a language… we reduce their life’s work down to one number, and then that number is wrong. They are obviously going to be upset by that! But I think there are two approaches to that. One is to be very defensive, and say that, no, the statistics is objective, it’s better, it’s more scientific. I don’t think that’s really the right answer, either. I think there’s a middle ground: what I’ve been calling the maximum robustness approach to statistics. It’s that kind of thing: to try and look at as much data as you can, as many different sources as you can, and be continuously open and honest to accepting new sources of information.
DANIEL: So let’s talk about the Everett paper. Now I mentioned that you worked with Caleb Everett on the second one. That’s the one that showed that when it’s really dry, we don’t see very many tone languages.
SEÁN: Yeah, sure. So actually I came on to the paper about tones and climate as a skeptic. Caleb had written this post about high-altitude phonemes.
DANIEL: Yeah, there was his round one.
SEÁN: And I was very skeptical about this. I wrote a blog post. He got in touch with me, and said, “Do you want to work on this other paper together?” And I was convinced we’d disprove this pattern, but we built the statistical analysis and the pattern seemed like it was there in that particular dataset.
DANIEL: I just want to say something at this point. He does this! Right? Like, because we talked about that same paper at first, and we were like, “No, this is not a thing.” And he got in touch with us and said, “Hey, do want to talk about it?” So he really does engage. I so respect that!
KYLIE: It is so unlike what you might expect from people on the internet, where they might just jump in to your blog conversation: “No, it’s not!” Actually, let’s look at it further! Come on, let’s collaborate. Wow.
SEÁN: Yeah, I think that’s one thing that… so, people who look at big data have quite a lot of distance from the data. And if one data point, they’re told that something is wrong, that’s fine. We change it. We redo the analysis. If some part of the statistical analysis is wrong, and someone tells us… great! We can revise things. We don’t need to protect our own particular theory. I don’t really have much of a stake in this hypothesis, apart from being interested in testing the general idea of whether you can find whether languages adapt to things outside of language, using big data.
DANIEL: So my understanding is that you grabbed a different dataset, re-ran the experiments, and the pattern wasn’t there.
SEÁN: Yeah! So it’s been very entertaining watching your reactions to this as the theories have been coming and going from sort of like, “Oh, that’s interesting! Oh, that’s definitely not right. Oh, that’s interesting!” And now I’m here to tell you that, “Oh, it might not be right!”
DANIEL and BEN: Yay! Whoa! Aaaa! Oh!
DANIEL: I am having all the feels about this. I’m having emotional whiplash.
KYLIE: It’s the best roller coaster you can imagine. A science one.
SEÁN: Yeah, and so in the original data set, it looks like there was a pattern there that you wouldn’t expect by chance. But the big question was: does that replicate? So in psychology, this is a really important thing now. If you come up with an explanation for something, you also want to go away and grab a bunch of new people from the same experiment, and see if you get the same result. But that’s kind of tricky in linguistics because we only have something like seven thousand languages to start with. Once we use those up, that’s it. And it’s very unlikely that you’re going to get multiple datasets that are independent from each other, and are big enough to run the same analysis.
BEN: So then how did you do it?
SEÁN: Well, in this case we’re lucky, because there are two datasets that cover thousands of languages and measure the number of tones in a language. The original one we used came from the Australian National University, and the new one I’m using is the PHOIBLE database (phoible.org), which is a big database for phonetic inventories… phoneme inventories… and that has the number of tones. So we could just rerun the same statistics, and see whether the pattern was there. And obviously if the theory is right, then we should be able to replicate the same results. But in fact, we didn’t. We reran the statistics and it wasn’t significant. The effect was much smaller, the pattern was much weaker than it was before.
BEN: So is that down to the dataset? Is ANU’s data set restricted? Is it insufficient? Like, I guess my question is: do we just expect little hiccups like this when running big dataset… like, is it an anomaly, essentially?
SEÁN: That’s a really good question. So what I did was, I compared the two datasets, and actually they disagree on how many tones a language has.
BEN: Oh.
SEÁN: The correlation between the two datasets is pretty small. And I think that’s understandable, because measuring the number of tones a language has is very difficult. You have to look at the system, your analysis of what counts as a toneme, the background of the researcher might differ. And then on top of that, there might be coding errors or extra errors that the people who put the database together made on top of that.
BEN: Well, I mean that begs the question then — because it just keeps getting deeper really, doesn’t it? — like, there’s nothing — again to the lay person — there’s nothing that I’ve heard so far that suggests ANU’s data set is the wrong one, necessarily. So if they disagree on the number of tones, and that’s kind of what’s sitting behind the difference in the outcome of this hypothesis run — like, do we know that ANU’s data set has got it wrong?
DANIEL: It just depends on your analysis, in some cases.
SEÁN: No, no! So, I guess there will be errors in some cases. But I think they’re just two different analyses of the same language.
DANIEL: And that shouldn’t matter that much. I mean, you could have slightly different analyses, and it would still work out okay as long as you’re following some kind of method.
BEN: But it hasn’t worked out okay in this instance, right? Because it spat out two fairly different answers.
DANIEL: And that tells us that this hypothesis — that climate influences tone — is not very robust. The significance fell on the other side of the line this time, I guess.
SEÁN: Yeah, that’s right.
DANIEL: So is that it for geophonetics? Is it done?
SEÁN: [LAUGHS] Not at all, no. It just means that, in this case, measuring the concept is pretty hard. We just don’t have a reliable way to measure the number of tones.
DANIEL: This is really fascinating stuff. We need to take a little break and listen to a track. When we come back, I would like to talk more generally about: if I’m doing experiments, which I do, how can I avoid certain kinds of problems? So can you hang out and listen to a song with us?
SEÁN: Sure, great.
DANIEL: Since we’re talking about big data, let’s listen to ‘Big House Waltz’ by Deerhoof on RTRFM 92.1. Now remember, if you have any questions about what you hear, you can get those to us: 9260 9210 in the studio.
BEN: You can send us an email talkthetalk@rtrfm.com.au or jump on to Facebook and get in touch with us on our page.
KYLIE: Or you can go onto twitter, #RTRFM or @talkrtr.
[MUSIC]
BEN: We are talking big data in this week’s episode of Talk the Talk. We just spoke about a specific example of where big data was used to suggest — and then de-suggest — a new thing in linguistics. But now we’re talking generally. What can we do with big data, and be responsible and safe users?
KYLIE: Our guest on the show is Seán Roberts. He’s the author of ‘Robust, Causal, and Incremental Approaches to Investigating Linguistic Adaptation’.
DANIEL: Now, let’s talk about your ideas for how we can do slightly better. What suggestions do you have if I’m somebody who’s handling tons of data? We mentioned using alternative data sets. You’ve got to sort of try it with one set, then try it with another, if you got it.
SEÁN: Yup. And if you’re lucky enough to be able to do that, one thing you might find is that your measurement is robust. So that in two different datasets, you look at the same language and you get the same measurement. Now, that turned out not to be the case for the number of tones. So maybe we can look at another measure that’s also predicted by the theory. So you go back to the theory, you ask more generally: okay, we think that properties of the language might be related to climate. What other predictions are there? Is there other data out there where we can test this general idea? And what Caleb did was look at the proportion of vowels. So instead of looking at tones, you’ve got like: languages in drier climates should rely less on vowels to communicate which requires the vibration of the vocal folds, compared to consonants. And so I really like his new paper because it’s a sort of creative way of getting around this problem with tones — is by saying, okay, here’s another prediction. Here’s a different data source. And we can test that.
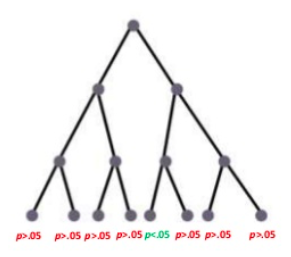
BEN: Seán, can I ask you: It brings to mind, though, a concern that people who might read a bit about science might have, in that the way — I don’t think you presented it this way just then, but it’s very conceivable that a person could put the cart before the horse. Right? And run a big old analyses on a big old dataset and see, “Oh there’s a thing here, and there’s a thing here, and there’s a thing here. I wonder what those things are.” And have a look at them and go, “Oh, that thing! We… could construct a hypothesis like this for it!” And I think that gets called p-hacking, as in ‘p’ as in like probability. So how do we stop that happening, because it doesn’t seem very sciencey.
SEÁN: Yeah, so you’re absolutely right. The sort of gold standard for science is to have a theory, generate a prediction, then collect your data and test where the theory is right. But I mean, it doesn’t always work like that, we find. Any theory starts with someone noticing patterns. Even if you’re a sociolinguist looking at… and you spot that certain types of people use a certain type of linguistic structure, that will then lead you to propose a theory, and then you gather data as to your hypothesis.
BEN: That’s true.
SEÁN: And you’re absolutely right. There is a lot… I get very excited when I get handed a big dataset, because of course the first thing you want to know is: what’s correlated with something else? Is there some big discovery here that we’re not looking at? And I think a lot of the problems that linguists had with the relationship between tone and climate was that it looked like a very left-field idea. And it looked like someone had spotted a pattern, and come up with a theory to fit it. Which… well, it’s sort of very hard to tell whether that’s true because of course we’re all experts in linguistics. We’ve all seen maps and data. All that information is there, ready to be used, to turn into theories. But from another perspective, the link between climate and language from… if you’re someone who studies laryngology and the sort of physiology of speech, that’s kind of a natural hypothesis to make. And if you look at animal communication studies, it’s quite well accepted that the environment that an animal lives in will affect the sounds that it makes. This general geophonetics sort of applies to animals, like birds and bats and primates, even. But it’s not a very mainstream thing in linguistics. So from someone’s perspective, it might look like it’s a very big jump in logic. From another perspective, it might look like a very small progress on the theory.
KYLIE: One of the things I really enjoyed about this paper was the conclusion, not only covering what you just said there in terms of… the aim is to provide many alternative viewpoints, not just to discover the most convenient statistic, which is something we’ve talked about in terms of fake news. We don’t just go for what’s convenient out there. But also at the end about how communication of research, especially to non-specialist audiences is such an important thing. And being clear and collaborating with people is so important. So I really enjoyed that summing up of the paper at the end.
SEÁN: Yeah, and it’s quite difficult task, because this robustness approach means theory and lots of statistics… lots of data thing and it’s really hard to summarise on that. What I said was, people should be very quick to take on board new information.
DANIEL: One thing that I really liked: You looked at the output of Larry King, the radio host. What was up with that?
SEÁN: Yup. Well, so the basic idea is that it’s very easy to spot patterns in big data, and then come up with a hypothesis based on that. And I think that’s fine, as long as you then go and test the hypothesis in a different database from the one you spotted it in. So here’s an alternative prediction based on Caleb’s work. Caleb would predict that Larry King would use more vowels when it’s more humid, and fewer vowels when it’s dryer. That’s the basic idea. And Larry King is interesting because he’s recorded a radio show nearly every day for a very long time. And there are transcripts of these for ten years. That’s a huge amount of data on one individual person. And if there was an effect, this would be the database where we could see it. I looked at the proportion of vowels that Larry King used every day, and then I looked up the actual humidity of LA on the day that he used them, and tested whether there was a correlation. But there wasn’t a correlation. In fact, the correlation went in the opposite direction than the one predicted.
BEN: Now, it needs to be noted though, that it could be, like, a million degrees outside and a hundred percent humidity, and right now in my studio it would still be comfortable.
SEÁN: Exactly. Yeah, there’s air conditioning. Those are problems with the study. But I thought it was kind of interesting, the general idea of the sort of toy example, you can make predictions from the general theory. You can test them in new creative ways with different datasets trying to converge on the same thing.
DANIEL: So the advice that I’m getting from your article goes something like this. Make sure that you have really robust associations by using alternative datasets. Don’t rely on ad hoc hypotheses. Don’t hack around in your p-values. What else?
SEÁN: Well, I guess one thing is the effect size. So you might get something… a very statistically significant correlation between two things. But if the effect size is small, then maybe it’s not really worth pursuing academically. So actually the relationship between the climate and vowels is quite statistically robust. But the effect size is tiny. Between the whole range of climates on earth, the effect of climate on language is really only one or two vowels in the phoneme inventory.
BEN: Whoa.
SEÁN: So the pattern is there, but it may not be the most important thing that we could focus on. Hopefully, you know, the big data gives us the chance to spot interesting patterns, or test really important theories in many ways. And I hope that’s what’s going to be the big contribution of big data.
DANIEL: The paper is ‘Robust, Causal, and Incremental Approaches to Investigating Linguistic Adaptation’. I really liked it. I wish that all people who go with big data have a chance to read it. And thanks so much for talking the talk with us today, Seán.
SEÁN: Thanks for having me on.
DANIEL: That was Seán Roberts from the University of Bristol talking about big data methods. What do you think?
BEN: Pretty interesting. I’m still a little bit concerned.
DANIEL: Concerned about what?
BEN: Look, human beings, as we know, are endlessly disappointing creatures. And so I worry that with this big juicy, like, academic steak sitting in front of people — that just goes, “Analyse me! Analyse me for all the best correlations that you could possibly find!” — it just seems like it’s too good, and a lot of people will be tempted. Because… look, academics are human beings; publish or perish. They’re going to be looking in there, being like, “Oooo, can’t find anything… oh, I found something! …I could just construct a hypothesis after.” And I’m still concerned. I’m still really concerned about p-hacking.
KYLIE: I was really enthusiastic about the paper because it challenges exactly those kinds of things in the entire make up of the paper. It’s saying you have to be able to take a step back. You have to remove the ego. You have to start realising, “Okay, well, what can the data show us?” even if it isn’t something that you think it is tending towards. You have to start moving out and collaborating with other people, and realise that communicating the data is incredibly challenging. We’re having non-specialists picking up this information, you’ve got the media diluting it in order to make a new story, and it’s something that needs further work. And that’s something that happens all the time in science communication. So I would use this as a model paper in terms of what is going on out there in terms of studies, and how to take a step forward for science and say let’s do it right.
DANIEL: It is. It’s so tempting to say, “Oh! I found a great correlation!” and then stop. And he’s saying that’s not good enough. You need to approach this from multiple angles. You need to use different datasets. And you need to not rely on ad hoc hypotheses in case you fail.
KYLIE: Talk to people from other specialities. Make sure that everyone’s on the same page in order to get the information out there. We’re talking about economists and linguists and people in the science communication field, statisticians. So yeah, how can we all work together in order to make it right?
BEN: Sounds like registration’s the key to me.
DANIEL: Registration?
BEN: Yeah, put your money where your mouth is. Put your hypothesis on the table, then you get the data, not before.
DANIEL: I like. I like.
BEN: They’re doing it in psychology. I don’t know if registration’s the right word, but you essentially register your intent as a researcher. You go, “I would like to test the following hypothesis,” and you date it, and then you get access to the candidates or the study or whatever.
DANIEL: That is a really brilliant idea. I love that idea. But it can only work if interesting negative results are valued.
BEN: Yes, absolutely. And we haven’t valued them.
DANIEL: No, we haven’t.
BEN: Not at all. Which is really criminal. Like, I really want to find out if caffeine is actually not a big deal or whatever, right? Like, things not being true? Really, really important.
DANIEL: I would love that! I would love to know. You know, it’s… I don’t have a dog in this fight. Does climate make a difference in language? Let’s just find out.
BEN: Yep.
DANIEL: No, we didn’t find anything? Cool! That’s an awesome answer.
BEN: Like, that’s just as valuable as finding a yes!
DANIEL: Yeah! Well, look I think we have a lot to think about here. Let’s listen to something, and this is Sharon Jones and the Dap Kings with Inspiration Information on RTRFM 92.1.
[MUSIC]
BEN: [VERY QUICKLY] Hey, everyone, it’s Talk the Talk, and it’s time for Word of the Week. BAM!
DANIEL: The Word of the Week this week is one that was just recently added to the Merriam-Webster dictionary. It’s from the Simpsons.
BEN: Ooo! Okay, wait. Stop.
DANIEL: Yes?
BEN: Hammer time. I want to figure out exactly what this word is, okay? I feel like, as a person the age that I am, I have watched literally every Simpsons episode multiple times.
KYLIE: Really?
BEN: Of course! You’ve got to remember, the Simpsons was on every single night, every night, for like ten years of my life. Right? Every night. Not every week. Every night. So, many many repeats. Anyway. I feel like “d’oh” is too easy. Too obvious.
DANIEL: That one did make it into the Oxford English Dictionary. The realisation that someone has done something foolish.
BEN: It’s not going to be cowabunga. It’s not going to be, like, have a cow.
DANIEL: This is going to be something that was invented specifically for the show.
KYLIE: It also happens to be the name of one of my favorite bookstores ever.
BEN: Oh… um…
DANIEL: And it was spoken by a certain teacher, Mrs Edna Krabapple.
BEN: Oh! Dah! I want to know this so bad but I want to guess it!
KYLIE: Ben’s tearing himself to pieces here in the studio!
BEN: [SOUL-WRENCHING SCREAM] Nah. I don’t know. I don’t know!
DANIEL: Let’s hear it.
MRS KRABAPPLE: Embiggens? Hm. Never heard that word before I moved to Springfield.
MISS HOOVER: I don’t know why. It’s a perfectly cromulent word.
BEN: I… aaaugh! I use embiggen! I use it! I use it all the time. I always use it when I refer to, like… when you’re scrolling through stuff on someone’s phone and it’s dumb and far away, and I’m like, just embiggen it!
DANIEL: Could you just embiggen that?
BEN: Oh, my goodness.
DANIEL: But now here’s the funny thing. The word ’embiggen’… it’s older than the show.
KYLIE: Really!
BEN: Yes, here we go.
DANIEL: The first time we see it is in 1884.
BEN: Wha…? To mean what we think it means?
DANIEL: I’ll read the original quote. This is from a book called ‘Notes and Queries’. “Are there not, however,” says this writer, “barbarous verbs in all languages. But the people magnified them to make great, or ’embiggen’ if we may invent an English parallel as ugly. After all,” says this author, “use is nearly everything.”
BEN: Ah, so it didn’t mean exactly the same thing, but there were using it as a burn.
DANIEL: Yeah, it was saying, “This is a really ugly word that I’m going to make up: embiggen. Ha!”
BEN: But you all understood it.
KYLIE: I liked the bit at the end where it said that use is everything. We’re getting the context.
DANIEL: Use is nearly everything, right? A word doesn’t just mean what a dictionary says it means. It means what that person intended it to mean when they used it in a community. People are starting to use ensmallen, as well.
KYLIE: Really?
BEN: Oh, that’s cool. Can you ensmallen it?
KYLIE: Cool.
DANIEL: You can ensmallen something. And the other big news in dictionaries is that emoji are being defined.
BEN: Yes! Oh, this is good. Can you give me an example though? Because we’ve discussed previously how there is a lot of semantic ambiguity around some emojis.
BEN: There is.
KYLIE: I’ve got one here. Nail-polish emoji. “Aside from tagging nail- and beauty-related images online, the nail polish emoji can serve as a tone marker indicating sass, fanciness, nonchalance, or self-confidence across a variety of digital contexts.”
BEN: So you might use the nail polish if you were just like…
KYLIE: Yeah, whatever, Ben!
BEN: Oh, I was actually thinking something different. So like, if you were sharing a post like, “Just at work today, boss told me that I’ll be moving up in the company, got home, home-cooked meal waiting for me by, like, the wonderful person and tonight my favorite movie just happens to be on TV. 💅 – nail-polish emoji.” Like just… like, man this person’s a queen!
DANIEL: I think it’s when you’re trying to play it cazh, as well.
BEN: Yeah, right.
DANIEL: I’m going to give you another one. You have to guess the emoji.
BEN and KYLIE: Okay!
DANIEL: Dictionary.com defines this as: “Represents an array of abstract and concrete concepts. Some of these are positive like gratitude, spirituality, and hopefulness. It may also be representative of pleading, asking for something….” Kylie’s got the gesture.
KYLIE: It’s the hands together in prayer.
BEN: Prayer hands.
DANIEL: Kylie’s got it. It’s the folded hands emoji. Very nice. How about this one: Dictionary.com defines this as: “It’s variously used across digital contexts to express a fun, party-loving spirit, communicate festive and friendly sentiments, and mark content dealing with adult entertainment.”
BEN: Sassy waiter lady?
DANIEL: No.
BEN: Not eggplant?
DANIEL: Nope.
KYLIE: It better not be upside-down smiley, because I put that on a lot of my messages and it might be highly inappropriate, now that I think about it!
DANIEL: Nope!
BEN: Smiley devil horns?
DANIEL: This is one with two people in it.
BEN and KYLIE: Oh!
BEN: I don’t know!
KYLIE: Are they dancing?
DANIEL: They are dancing.
BEN: Dancing people!
DANIEL: And they’re wearing the bunny ears.
BEN: What?
KYLIE: What? Okay, look, I don’t use that one. I’m looking at up.
DANIEL: Yep, it’s the ‘people with bunny ears’ emoji, which you have never seen before!
KYLIE: Yeah, where is it? Where is it?
DANIEL: Imagine the challenge of trying to define what these mean by looking at their use in situations.
BEN: Oh, that seems really challenging, but also kind of fun, a little bit! Like, you’ve got to imagine the person who works in a dictionary place is not necessarily the life of a lot of parties.
DANIEL: Oh, I don’t know. I’ve met them and they are awesome.
BEN: Are they the life of linguistic parties?
DANIEL: What are you saying?
BEN: I think you know exactly what I’m saying.
DANIEL: I think you better define that.
BEN: Yeah, like a dictionary person!
DANIEL: If you have any questions for us or anything you want to add, go ahead and give those to us. I am watching the email: talkthetalk@rtrfm.com.au
KYLIE: You can phone Daniel on 9260 9210.
BEN: I will never stop encouraging you to come to our Facebook page, because all of the people who are already there are tremendous human beings, and you are also a tremendous human being, so you should be in good company. And if you want, you can also tweet @talkrtr.
DANIEL: But now, let’s take a track. This is Ibeye with ‘No Man Is Big Enough for My Arms’ on RTRFM 92.1.
[MUSIC]
DANIEL: It’s the tail end of Talk the Talk. I’m still sort of sitting here, kind of ruminating on what we’ve been talking about. I can’t help but feel that what I do — the science communication — is part of a problem, because there’s a need to have your results be very sexy. If your results aren’t sexy enough they get ignored, but if your results are too sexy, then you’ve probably done something wrong because, as Ben mentions, truth is very boring. So I wonder if there’s a way that we on Talk the Talk and other linguistics podcasters can help to tamp down the sexiness to find the interest in the real story. Ah, it’s a constant challenge.
I was also thinking about Caleb Everett’s idea of geophonetics. We found that in experiment two, humidity and tone, Seán Roberts found that the effect was not very robust. And with humidity and vowels, he found that the effect size was not very big. And it left me with a lot of questions. So I got in touch with Caleb Everett. I just wanted to know what he thought about the Roberts work and he sent me back an email. I’ll just read a bit of it.
CALEB EVERETT: “Seán’s paper is a really nice addition to the discussion, overall. One of the things I appreciated about my collaboration with him and Damian Blasi on this topic is that we’re all interested in the story the data have to tell. Whatever picture the data ultimately paint, hopefully we avoid theoretically-driven but data-weak accounts of this topic.
“What is great about Seán’s paper is that he offers several new ways of analyzing the data. There are some minor weaknesses, as with most papers. One weakness is not Seán’s fault and it is a weakness shared by the PNAS paper he and Damian and I co-wrote: The limitations of the extant databases on tone. It is unclear why there is such disagreement across these databases but ultimately the disagreements may stem in part from the difficulty of doing fieldwork on tonal languages. For instance, I know of a language in Amazonia (where I’ve done fieldwork) which one fieldworker described as having twelve phonemic tones, and another fieldworker described as having two tones. So, depending on the sources utilized, one can see how tone databases could offer very disparate results…. Again, though, in general I quite like the paper because it offers many useful ways that we can continue to shine light on the relevant data, wherever they lead.”
Well, that is, I think, the right sort of thing. Whether this idea is ultimately right or wrong is the thing that matters, and not who is right or wrong. So hats off to everyone engaged in the good work of science.
I’d like to thank you also for listening to this episode of Talk the Talk. I’d like to thank Seán Roberts especially for getting in touch, and if you are a sciencey person, please — we are listening! I hope that you’re listening to old episodes. You can find those on our blog, talkthetalkpodcast.com, we are on Patreon, and we are also doing lots of stuff on Facebook, so get in touch with us there. Thanks for listening, and until next time, keep talking.
[OUTRO]
BEN: This has been an RTRFM podcast. RTRFM is an independent community radio station that relies on listeners for financial support. You can subscribe online at rtrfm.com.au/subscribe.
KYLIE: Our theme song is by Ah Trees, and you can check out their music on ahtrees.com, and everywhere good music is sold.
DANIEL: We’re on Twitter @talkrtr, send us an email: talkthetalk@rtrfm.com.au, and if you’d like to get lots of extra linguistic goodies, then like us on Facebook or check out our Patreon page. You can always find out whatever we’re up to by heading to talkthetalkpodcast.com
[Transcript provided by SpeechDocs Podcast Transcription]
Image credit: https://www.slideshare.net/JimGrange/10-recommendations-from-the-reproducibility-crisis-in-psychological-science







